
Ultimate Guide to Disaster Recovery in Azure: Safeguard Your Data with Expert Tips
Disasters are unavoidable. Whether it’s a natural calamity, a cyberattack, or a human error, any event that disrupts your business operations can have serious consequences. You may lose data, revenue, reputation, and customer trust. That’s why you need a disaster recovery plan that can help you restore your services and data as quickly and smoothly as possible. In this article, we will provide an Ultimate Guide to Disaster Recovery in Azure: Safeguard Your Data with Expert Tips.
What is Disaster Recovery?
Disaster recovery (DR) is the process of restoring normal operations of an organization after a major disruption, such as a natural disaster, a cyberattack, or a human error. It is essential for ensuring business continuity and minimizing downtime and data loss.
Small and medium businesses can implement disaster recovery to the cloud using Azure site recovery. Healthcare, travel, hospitality, and manufacturing are some of the industries which are ideal for this disaster recovery solution.
Here we have an architectural diagram through which you will understand how disaster recovery works:

Traffic Manager allows you to distribute traffic to your public-facing applications across the global Azure regions. This also provides your public endpoint with high availability and quick responsiveness.
In the above diagram, you will see that the DNS (Domain Name System) traffic is routed via Traffic Manager, which will move the traffic from one site to another site based on policies defines by your organization. The traffic manager uses DNS to direct the client request to the appropriate service endpoint based on the traffic-routing method.
Azure Site Recovery will arrange the replication of machines. Replication means copying the data from a primary site to a secondary site so that if a disaster occurs, the secondary site can quickly take over and continue the operations.
Azure site recovery will also manage the configuration of the failback procedures. Failback means returning the operations to the primary site after a failover process. Here are the steps:
- Tracking changes made to the primary site during the failover process.
- Synchronizing the data between primary and secondary sites.
- Testing failback process to make sure that it won’t cause any disruption to operations.
A secondary site creates a similar network architecture including virtual networks and subnets so in case of failure, the failover process will create the workloads when a disaster occurs. By using a Virtual Network, organizations ensure their failover site is created in a secure and isolated environment that can be easily managed and configured. Virtual Network helps to securely connect Azure resources, on-premises resources, and other networks.
Blob Storage will store the replica images of all machines that are protected by site recovery. These replica images are point-in-time snapshots of the machines and contain all the data, configurations, and applications that are required to restore the machines to the previous state.
What is Azure Site Recovery?
Azure Site Recovery (ASR) is a cloud-based Disaster Recovery service that helps organizations protect their applications and data by replicating them to Azure. It also supports replication, failover, and recovery processes across Azure regions, availability zones, and continents, giving you more flexibility and resilience.

Azure Site Recovery replicates important workloads and data to Azure, which serves as a secondary data center. In the event of a disaster, businesses can point to a secondary Azure site to access their replicated workloads and data. This service supports various types of workloads, including virtual machines, physical servers, and Linux workloads, and it provides two replication options: continuous and scheduled replication. Continuous replication synchronizes changes to important workloads and data with Azure in near real-time, while scheduled replication allows businesses to replicate workloads and data according to their preferred schedule, which is useful for meeting specific recovery point objectives (RPOs).
Azure Site Recovery provides a powerful disaster recovery solution to help organizations prepare for and recover from disasters. It provides automated protection and replication to protect your critical workloads and ensure that they remain available and resilient in the face of a disaster.
Azure Site Recovery provides several benefits, such as:
- Cost-efficiency: You only pay for the storage and compute resources that you use for replication and failover. You can also leverage Azure Hybrid Benefit and Reserved Instances to reduce your costs further.
- Scalability: You can replicate and failover as many workloads as you need, without worrying about capacity or performance limitations. You can also use Azure Automation to orchestrate complex recovery scenarios involving multiple workloads and dependencies.
- Flexibility: You can choose from different replication and recovery options based on your business requirements and recovery objectives. You can also customize your recovery plans with scripts and Azure runbooks to automate tasks and workflows.
- Security: You can encrypt your data at rest and in transit using Azure encryption services. You can also use Azure role-based access control (RBAC) and Azure Active Directory (AAD) to manage permissions and identities for your recovery operations.
Planning for Disaster Recovery
Planning for disaster recovery is an essential part of any organization. Disaster can strike anytime which can cause significant disruption to business operations, resulting in data losses. Therefore, it is important to have a comprehensive disaster plan that can help the organization quickly recover systems and data. To plan for disaster recovery you need to consider the following aspects:
Identifying critical workloads
Not all workloads are critical for your operations. Some workloads may require higher priority and faster recovery than others. For example, you have a customer-facing website that generates revenue for your business and a backend database that stores data for reporting purposes. In a disaster scenario, you want o restore the website as soon as possible.
So, by classifying your workload based on its importance, you can optimize your disaster recovery strategies and resources. Azure Site Recovery provides several features and tools to help you identify and prioritize your critical workloads. For example, you can use tags to group and filter your replicated items based on their criticality level. You can also use recovery plans to orchestrate the failover sequence and order of your workloads. Additionally, you can use test failovers to validate the functionality and performance of your workloads in the secondary location.
Choose a Disaster Recovery Strategy
Disaster recovery is a plan that outlines how to prepare for, respond to, and recover from such events. Choosing a disaster recovery strategy is important because that can affect the availability and performance of your business. There are different types of disaster recovery strategies depending on the level of protection and recovery time you need. The most common strategies are:
- Recovery Point Objective and Recovery Time Objective
- Replication
- Failover
Recovery Point Objective (RPO) and Recovery Time Objective (RTO)
Recovery Point Objective (RPO) measures the maximum amount of data loss that a business can tolerate in the event of a disaster or system failure. On the other hand, Recovery Time Objective (RPO) measures the maximum amount of time a business can afford to have its systems or applications unavailable or offline.
RPO and RTO are determined by the business impact analysis (BIA) that identifies the critical applications and processes that support the business, and the potential impact of downtime or data loss on them. Based on the BIA, the disaster recovery strategy can be designed to meet the desired RPO and RTO targets.
Azure Site Recovery helps to achieve low RPO and RTO by continuously replicating data from the source site to a target site in a different region. The source site can be either Azure or on-premises, and the target site can be either Azure or a secondary data center. ASR also allows you to create recovery plans that define the order and steps for failover and failback operations.
Replication Process
Replication is a process of copying all the data and applications from a primary Azure region to a secondary region in case of a disaster or outage. The replication process can be used for:
- Data Replication: Copying data from one disk to another disk or from a disk to the cloud.
- Application Replication: Copying applications components such as files, and registry setting from physical storage to the cloud.
- Database Replication: Copying tables and indexes from an on-premises database to a cloud database.
By replicating VMs to a secondary location, organizations can ensure that critical systems and data are protected in the event of a disaster. The Site Recovery Mobility service enables the replication process and continues the replication to ensure that changes to the VM are transferred to the secondary location in real time.
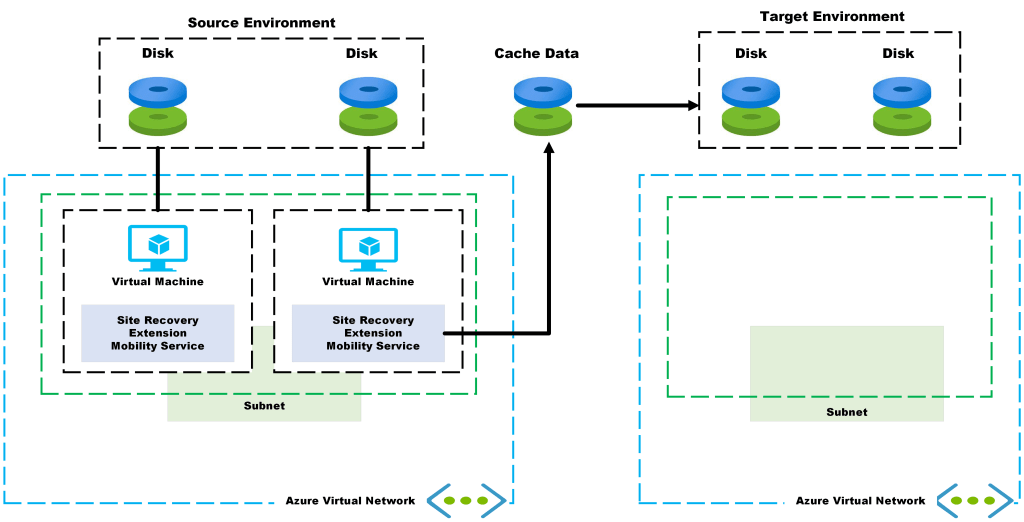
Enabling the replication process for an Azure Virtual Machine, the following things happen:
- The Site Recovery Mobility service extension is automatically installed on the VM.
- The extension registers the VM with Site Recovery.
- Continuous replication begins for the VM. Disk writes are immediately transferred to the cache storage account in the source location.
- Site Recovery processes the data in the cache, and sends it to the target storage account, or the replica managed disks.
- After the data is processed, crash-consistent recovery points are generated every five minutes.
- App-consistent recovery points are generated according to the setting specified in the replication policy.
Now let’s understand what is crash consistent and what App consistent snapshot.
Crash Consistent: A crash-consistent snapshot captures data that was on the disk when the snapshot was taken. It doesn’t include anything in memory. Azure site recovery creates crash-consistent recovery points every 5 minutes by default. This setting cannot be modified. Also, crash-consistent doesn’t guarantee data consistency for the OS or apps on the VM.
App Consistent: An app-consistent snapshot contains all the information in a crash-consistent snapshot, plus all the data in memory and transactions in progress. They are more complex and take longer to complete than crash-consistent snapshots.
Failover Process
Failover is a process of switching to a backup system when the primary site fails. The goal of failover is to minimize the impact of a disruption on the user and the business services. Failover can be automatic or manual, depending on the configuration.

When you initiate a failover, the VMs are created in the target resource group, target virtual network, target subnet, and in the target availability set. During a failover, you can use any recovery point.
Manual Failover
Manual failover for disaster recovery uses the standard DNS mechanism to fail over to the backup site. The manual option via Azure DNS works best when used in conjunction with the cold standby or the pilot light approach.

In the above diagram,
- The DNS server is located outside of the failover or disaster zone. This will ensure that the DNS server is insulated against any downtime.
- A cost-effective failover scenario will work all the time assuming that the operator has network connectivity during a disaster and can make the flip.
- If the solution is scripted, the server or service running the script should be insulated against the problem affecting the production environment.
- The low TTL set against the zone ensures that no resolver around the world keeps the endpoint cached for a long, enabling customers to access the site within the recovery time objective (RTO).
- For a cold standby and pilot light, prewarming and other administrative activity may be required before making the flip, so enough time should be given to ensure a successful transition.
Automatic Failover
When you have complex architectures and multiple sets of resources capable of performing the same function, you can configure Azure Traffic Manager to check the health of your resources and route the traffic from non-healthy resources to healthy resources. For instance, you have a full deployment in both primary and secondary regions, including cloud services and a synchronized database. Azure Traffic Manager (based on DNS) checks the health of your resources and redirects traffic from non-healthy resources to healthy ones.

During a disaster scenario, several events take place to ensure continuity and avoid downtime. First, the primary endpoint gets probed, and the status changes to degraded. Meanwhile, the disaster recovery site remains online and available to receive traffic.
By default, Traffic Manager sends all traffic to the primary endpoint, which is the highest-priority one. However, if the primary endpoint appears degraded, Traffic Manager triggers a failover process and routes the traffic to the second endpoint. This happens as long as the second endpoint remains healthy.
Moreover, one can configure additional endpoints within Traffic Manager that can serve as extra failover endpoints or load balancers, allowing sharing of the load between endpoints. This adds an extra layer of resilience to the system, reducing the risk of downtime and ensuring continuous availability.
Azure Site Recovery provides different failover options, such as:
- Test Failover: Used to run a drill that validates your BCDR strategy, without any data loss or downtime.
- Planned Failover-Hyper-V: Usually used for planned downtime. Source VMs are shut down. The latest data is synchronized before initiating the failover.
- Failover Hyper-V: Usually run if there’s an unplanned outage, or the primary site isn’t available. Optionally shut down the VM and synchronize final changes before initiating the failover
- Failover VMware: Usually run if there’s an unplanned outage, or the primary site isn’t available. Optionally specify that Site Recovery should try to trigger a shutdown of the VM, and synchronize and replicate final changes before initiating the failover.
- Planned Failover-VMware: You can perform a planned failover from Azure to on-premises
Setting up Disaster Recovery in Azure Site Recovery
Setting up disaster recovery in Azure Site Recovery can be a critical step toward ensuring business continuity in the face of unexpected disruptions. By replicating important workloads and data to Azure, businesses can quickly recover from disasters with minimal data loss. With Azure Site Recovery’s support for various types of workloads and flexible replication options, businesses can tailor their disaster recovery strategy to meet their unique needs. So, whether it’s continuous replication or scheduled replication, Azure Site Recovery can help businesses set up a robust disaster recovery plan that provides peace of mind and protects their valuable data.
The basic steps to set up disaster recovery in Azure Site Recovery are:
STEP 1: Create Azure Site Recovery vault
A Recovery Services vault is a storage entity in Azure that houses data. The data is typically copies of data, or configuration information for virtual machines (VMs), workloads, servers, or workstations.

To create the vault, navigate to the Azure portal, select Create a resource, search for site recovery, and follow the instructions.
STEP 2: Enable replication for your VMs in the source region
Once you have created a vault, it is time to configure it by enabling replication, or what Azure refers to as Site Recovery. This involves installing the Azure Site Recovery Provider on your source machines, configuring replication settings such as recovery points, and starting replication. This process ensures that changes made to the source machines are replicated in the target region.
STEP 3: Configure the target environment
This involves creating a target resource group, virtual network, and storage account in the target region. You will also need to install the Site Recovery Provider on the target machines and configure replication settings for the target VMs.
STEP 4: Create a failover plan
Create a failover plan that specifies the order and dependencies of your VMs.For example, Database needs to be recovered first before restoring the VM otherwise VMs will not be able to connect to Database and the application will fail. You can also customize the network settings and post-failover tasks, such as DNS updates and load balancer configuration.
Perform a test failover to validate your recovery plan and ensure that your applications are functioning correctly in the target region. This can be done without impacting your production environment.
In case of a disaster or outage, you can initiate a failover from the Azure Site Recovery portal or PowerShell. This will stop replication, shut down the source VMs, and create new VMs in the target region using the latest recovery point.
STEP 5: Failback
When the source region is available again, you can fail back to it by reversing the replication direction and performing another failover. Azure Site Recovery will synchronize the changes that occurred in the target region back to the source region, and create new VMs there using the latest recovery point.
Keeping your Data Safe in Azure Site Recovery
With the rise of cyber threats and disasters, ensuring the safety and availability of your data has become a top priority for organizations. Here we have some of the solutions or methods which will help you to keep your data safe:
- Use Azure Policy to enforce disaster recovery best practices, such as configuring replication and regularly testing the Disaster Recovery plan.
- Use recovery plans to define the order and dependencies of your multi-tier applications, and to automate failover and failback operations using scripts.
- Monitor the health and replication status of your protected VMs using Azure Monitor alerts and dashboards.
- Test your Disaster Recovery plan periodically without affecting production workloads or end users, using test failovers.
- Optimize your RPO and RTO by adjusting the replication frequency, retention settings, and recovery point settings according to your business needs.
- Use application-consistent snapshots to ensure that your applications are in a consistent state after failover.
- Use Azure Backup to protect your data from accidental deletion or corruption during replication or failover.
Conclusion
Implementing Disaster Recovery in Azure Site Recovery will protect your data and ensure business continuity in case of a disaster. In this article, we have discussed Disaster Recovery and Azure Site Recovery, You have learned how you can plan for disaster recovery and how to set up disaster recovery in Azure Site Recovery. These different methods can be used to keep your data safe.
+ There are no comments
Add yours