
Why the Databricks Delta Live tables are the next big thing?
This is part one of a series of blogs for Databricks Delta Live table. In this blog, I have discussed the Databricks Lakehouse platform and its Architecture. What are the challenges involved in building the data pipelines and how Databricks Delta Live Table solves them?
How Delta live table offers ease of development and treats your data as a code. With Delta Live tables now you can build reliable maintenance-free pipelines with excellent workflow capabilities.
We will learn the different concepts and terminology used in Delta Live tables: Pipelines, Settings, Datasets, Pipeline Modes, and different editions of Delta Live Pipelines.
Finally, we will learn how Delta live tables provide unique capabilities to monitor the environment.
Lakehouse platform
To understand the Lakehouse platform we have divided it into multiple layers:
The first layer is the ingestion layer where we can use any Open Data Lake format or cloud provider providing similar functionality i.e. AWS, Azure or Google Cloud, or Open data lake. This is the first layer where the Structured, Unstructured, and Semi-Structured data is ingested.
Once the data is available for processing it goes thru the Databricks platform. We have three layers there
Platform Security & Administration: This is where you have the security and access control kept. This also helps to administer the system in terms of cluster size and other admin-related tasks.
Data Management and Governance: Data management and optimization are performed by Databricks Delta lake. Delta Lake is an abstract layer on the top of the Data lake that provides unique optimization features like Z-Order, Concurrent Read/Write, Upsert, and Snapshot isolation.
Consumption layer: This layer has integrated and collaborative role-based experiences spanning different consumption components interacting with Delta lake for data consumption. Data engineers and Data Scientists interact with Delta lake for Data engineering and Data science experiments respectively. Similarly, Machine learning, SQL Analytics, and Real-time data application interact for their data needs with Delta Lake.

A typical Lakehouse Architecture
In a typical Lakehouse architecture when the Data is ingested from various source systems it goes thru various zones before it is getting processed:
- Bronze: It contains the raw data as it is received for audit purposes to trace back to the data sources.
- Silver: This zone filters and cleans the data from the Bronze zone. Essentially it handles the missing data and standardizes clean fields. If there are nested objects it converts them into flat structures for ease of querying. It also renames the columns to familiar names so it is well understood.
- Gold: When the data reaches the Gold zone it creates the business-specific model and aggregates it based on Dimensions and Facts. It also provides business-friendly names and creates views for business users can access these views.

Complexity in building data pipelines
Maintaining Data Quality and Reliability at a large scale is very complex in data pipelines because:
- If one Pipeline fails, it affects the downstream system and the team relying on it.
- Tedious work is required to convert SQL queries to ETL Pipelines.
- Focus on Tools instead of doing the development because operational complexity dominates.

In summary, we have these three complex issues while building the data pipelines.

What are Delta Live Tables?
Delta Live Table is a simple way to build and manage data pipelines for fresh, high-quality data. It provides these capabilities:
- Easy pipeline development and maintenance: Use declarative tools to develop and manage data pipelines (for both batch & streaming use cases).
- Automatic testing: With built-in quality controls and data quality monitoring
- Simplified operations: Through deep visibility into pipeline operations and automatic error handling
Dependencies between sources and ease of development
Delta Live understands the dependencies between the source datasets and provides a very easy mechanism to deploy and work with pipelines:
- Live Table understands and maintains all data dependencies across the pipeline.
- Declaratively build data pipelines with business logic and chain table dependencies (in SQL, Python, Scala).
- Easy to run in batch or streaming mode.
- Specify incremental or complete computation.
- Reuse Pipelines.
- Develop in IDE locally or in Databricks Notebook.

Treat your data as code and Trust it
As per the industry best practice if you treat your data as code it is easy to maintain and provides flexibility in the development. Changing the code will automatically shape the data.
- A single source of truth for more than just transformation logic
- Prevent bad data from flowing into tables with Delta expectations.
- Detect and handle quality errors with pre-defined error policies (FAIL, DROP, or QUARANTINE Data).
- Visually inspect Lineage Query Event Log and report on Lineage across pipeline runs.
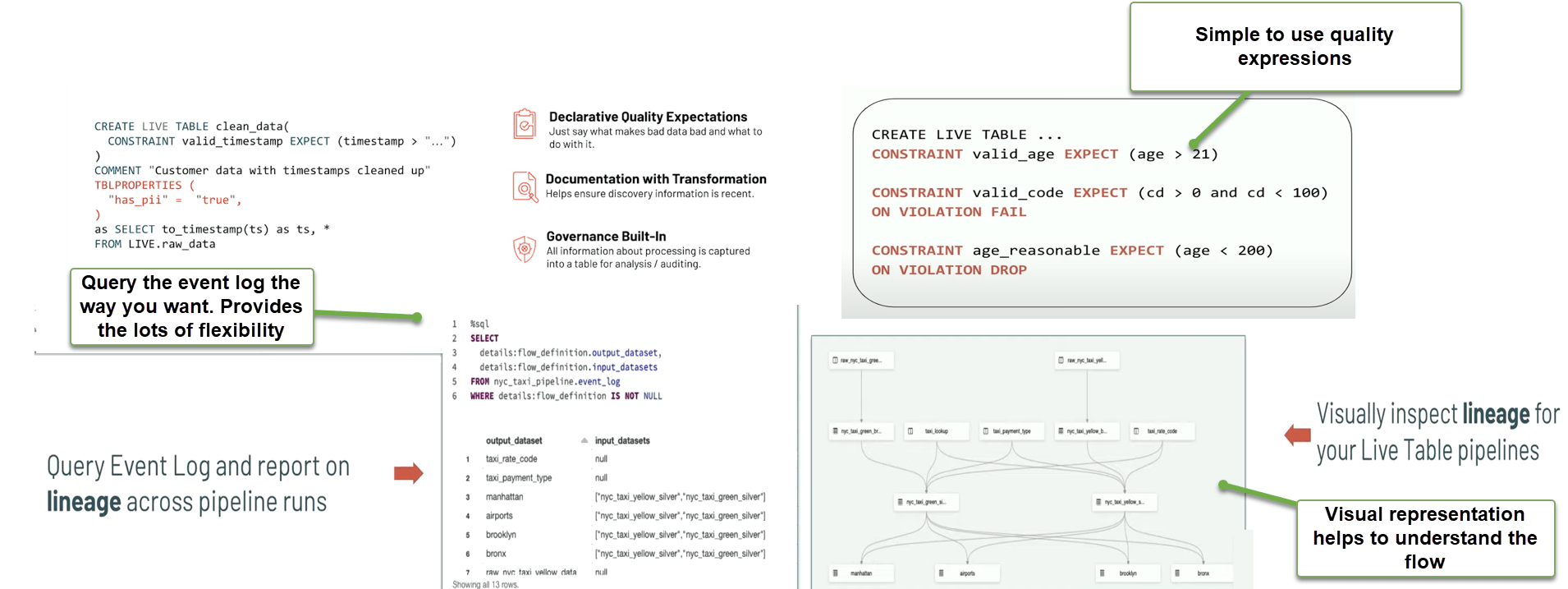
Reliability, Maintenance and Workflow management
Delta Live tables provide automatic error handling and easy to replay the ETL pipelines so it reduces the downtime significantly. It also eliminates the maintenance requirement because Delta Tables does its own set of maintenance activities out of the box.
- Reduce Downtime: With automatic error handling and easy replay, it helps to reduce downtime.
- Eliminate Maintenance: Databricks Delta lake helps to optimize Delta Live table operations reducing optimization overhead.
Workflow Management
Delta Live helps to integrate the orchestrator and Databricks in a single console so we do not have to maintain two different systems(orchestrators like ADF, Apache Airflow, and Databricks) to run our pipelines. maintaining two different systems makes it challenging to monitor and debug and becomes a costly solution because you need to purchase and maintain two solutions.

Delta Live Tables Concepts
Let’s understand the terminology used in the Delta Live table:
Pipeline
The pipeline is a Directed Acyclic Graph linking data sources to target datasets.
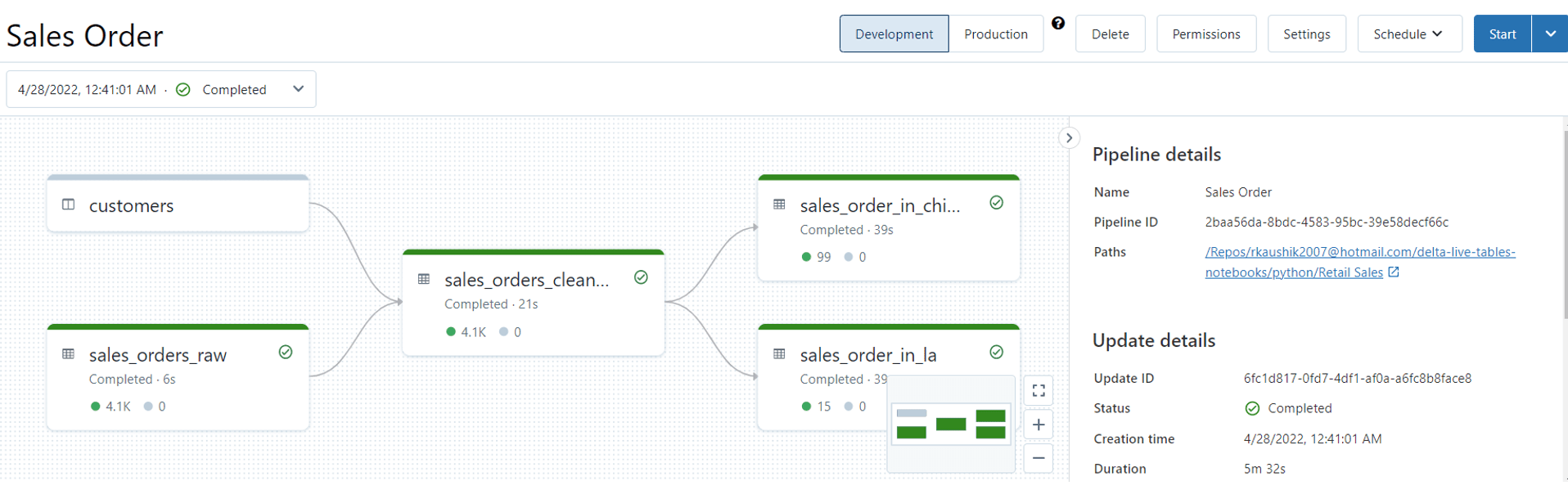
Pipeline setting
Pipeline configurations are defined in the Pipeline settings i.e. Notebook, Target DB, running mode, Custer config, and configurations(Key-Value Pairs). Here is an example of the typical pipeline settings:

Dataset
Delta Live supports two types of Datasets:
- Views: Views are similar to temporary Views in SQL. It helps to break down the complicated query into smaller or easier-to-understand queries.
- Table: Traditional Materialized views. Tables are created in Delta Format.
There are two types of Views and tables:
- View and Table Types:
- Live: Reflects the results of the query that defines it.
- Streaming: Processes data that has been added only since the last pipeline update. They are stateful. If query changes data changes.

Pipeline Modes
Delta Live provides two modes for development:
- Development mode: Reuses the cluster to avoid the restarts & disables the pipeline retries to detect and fix errors.
- Production Mode: Restarts the cluster for recoverable errors (i.e., Memory leak or stale credentials) Retries execution in case of specific errors.

Editions
Delta live has these editions and customers can use any of these editions depending on their requirements:
- Core: Good for streaming ingest workload
- Pro: Good for streaming ingest, CDC, Updating table based on changes in source data + all core features.
- Advanced: Supports Core & Pro feature with the addition of data quality constraints (Delta Live Table expectations)

Delta Live Event Monitoring
The event log for a Delta Live Table Pipeline is stored in /system/events under the storage location. Here is the thumb rule:
| If Pipeline Storage is configured at this location | Event Location of event |
| /Users/Username/Data | /Users/Username/Data/system/events path in DBFS |
| If Storage setting is not configured explicitly | Event Location of event |
| /pipelines/pipelineid/ | /pipelines/pipelineid/system/events |
By default, if the pipeline is not configured explicitly Databricks will create it in the /pipelines/pipelineid/ location.
Very nicely documented, easy to understand with image representations. Thanks for the document which helped me understand about the Delta Live Tables.
[…] (Courtesy: https://rajanieshkaushikk.com/2022/06/24/why-the-databricks-delta-live-tables-are-the-next-big-thing…😉 […]
[…] Referenceshttps://accounts.cloud.databricks.com/registration.htmlhttps://docs.microsoft.com/en-us/azure/databricks/workflows/delta-live-tables/https://www.databricks.com/discover/pages/getting-started-with-delta-live-tableshttps://rajanieshkaushikk.com/2022/06/24/why-the-databricks-delta-live-tables-are-the-next-big-thing… Contact Us […]