
How to deploy SQL Server containers to a Kubernetes cluster for high availability?
In this blog, we will learn how to deploy the SQL server container on Azure Kubernetes services with High availability. We will use the persistent storage feature of Kubernetes to add resiliency to the solution. In this scenario, if the SQL server instance fails, Kubernetes will automatically re-create it in a new POD and attach it to the persistent volume. It will also provide protection from Node failure by recreating it again. If you are new to Kubernetes we will start by understanding the basic terminology of Kubernetes and its Architecture.
Here is the basic terminology used in the Kubernetes.
| Term | Description |
| Pools | Groups of nodes with identical configurations. |
| Nodes | Individual VM running containerized applications. |
| Pods | A single instance of an application. A pod can contain multiple containers. |
| Deployment | One or more identical pods are managed by Kubernetes. |
| Manifest | YAML file describing a deployment |
This is depicted in the diagram below:

SQL server deployment
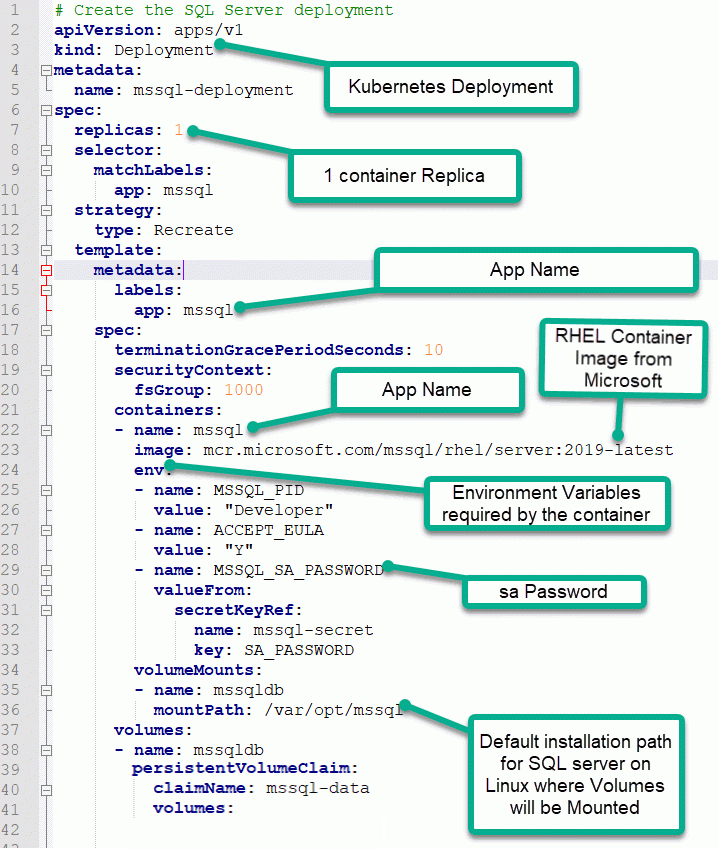
We will use this deployment configuration file to deploy the SQL server.
# Create the SQL Server deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: mssql-deployment
spec:
replicas: 1
selector:
matchLabels:
app: mssql
strategy:
type: Recreate
template:
metadata:
labels:
app: mssql
spec:
terminationGracePeriodSeconds: 10
securityContext:
fsGroup: 1000
containers:
- name: mssql
image: mcr.microsoft.com/mssql/rhel/server:2019-latest
env:
- name: MSSQL_PID
value: "Developer"
- name: ACCEPT_EULA
value: "Y"
- name: MSSQL_SA_PASSWORD
valueFrom:
secretKeyRef:
name: mssql-secret
key: SA_PASSWORD
volumeMounts:
- name: mssqldb
mountPath: /var/opt/mssql
volumes:
- name: mssqldb
persistentVolumeClaim:
claimName: mssql-data
Here is the explanation of the file. This is quite self-explanatory.
Deploy Persistent Storage Volume and Persistent Storage Claim
We will use this file to create PV(persistent volume) and PVC (Persistent Volume Claim):
# Create the storage class and persistent volumne claim
kind: StorageClass
apiVersion: storage.k8s.io/v1beta1
metadata:
name: azure-disk
provisioner: kubernetes.io/azure-disk
parameters:
storageaccounttype: Standard_LRS
kind: Managed
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mssql-data
annotations:
volume.beta.kubernetes.io/storage-class: azure-disk
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
PVC and PV description is self-explanatory in that it uses Azure disk to create the claim and the size is 8 GB.

Deploy Load balancer service
We will deploy a load balancing service with this configuration.
# Create the load balancing service
apiVersion: v1
kind: Service
metadata:
name: mssql-service
spec:
selector:
app: mssql
ports:
- protocol: TCP
port: 1433
targetPort: 1433
type: LoadBalancer
This is equivalent to the SQL server service running on the SQL server. SQL server service always runs on TCP port 1433 we are using the same setting in the SQL load balancer service.

Basic Architecture of the Kubernetes
All the apps connect to the load balancing services and the service connects to the POD. POD is connecting to the PVC and PV. PV is deployed via azure disk.

What happens when the Container fails?
When a container fails Kubernetes can create a new POD and connect it to persistent volume storage. Since the previous container already saved the data into the persistent volume storage it works seamlessly.

What happens when Node fails?
Now suppose that the node failed then in that case it will switch to another node and recreate the POD in the different node and finally connect the node to the persistent volume storage.

Azure CLI to create the AKS and test the failure.
You can use this CLI code to create the SQL server on AKS and test it. I have provided extra commands at the end for troubleshooting. Please copy this file into VS code and save its extension with .azcli and run it in bash shell line by line. You need to keep three YAML files in the same folder. The content of the file is already provided above. The code is self-explanatory since I have provided comments in the code.
# Login to Azure
az login
# Create an Azure resource group
az group create --name SQL-RG --location westus
# Create a two node cluster
az aks create --resource-group SQL-RG --name SQLSVR --node-count 2 --generate-ssh-keys --node-vm-size=Standard_B4ms
# Get credentials for the cluster
az aks get-credentials --resource-group SQL-RG --name SQLSVR
# List nodes
kubectl get nodes
# Create the load balancing service
kubectl apply -f sqlloadbalancer.yaml --record
# Create external storage with PV and PVC
kubectl apply -f sqlstorage.yaml --record
# Display the persistent volume and claim
kubectl get pv
kubectl get pvc
# Optional: In case if you want to explore differennt choices of storage classes you can run this line otherwise you can ignore it
kubectl get storageclass
# Use Kubernetes secrets to store required sa password for SQL Server container. This is a best Practice
# If you want to delete the previously created secret use this one otherwise avoid it and go to next line
kubectl delete secret mssql-secret
# use complex password
kubectl create secret generic mssql-secret --from-literal=SA_PASSWORD="Welcome@0001234567"
# Deploy the SQL Server 2019 container
kubectl apply -f sqldeployment.yaml --record
# List the running pods and services
kubectl get pods
kubectl get services
# TO fetch details about the POD
kubectl describe pod mssql
# Copy the sample database to the pod
# You can download the AdventureWorks2014.bak file from this URL
# https://github.com/Microsoft/sql-server-samples/releases/download/adventureworks/AdventureWorks2014.bak
# Use curl command to download the database if you are using Linux otherwise use direct download link
# curl -L -o AdventureWorks2014.bak "https://github.com/Microsoft/sql-server-samples/releases/download/adventureworks/AdventureWorks2014.bak"
# Retrieve pod name to variable
podname=$(kubectl get pods | grep mssql | cut -c1-32)
#Display the variable name
echo $podname
#Copy the backup file to POD in AKS. In Linux SQL server is installed on this path. We use this POD Name: /var/opt/mssql/data/ to access the specific directory in the POD
fullpath=${podname}":/var/opt/mssql/data/AdventureWorks2014.bak"
# Just to verify the path.
echo $fullpath
# just to echo what are we doing
echo Copying AdventureWorks2014 database to pod $podname
# Remember to specify the path if your project is running in different directory otherwise we can remove this path and make it kubectl cp AdventureWorks2014.bak $fullpath
kubectl cp AdventureWorks2014.bak ${fullpath}
# Connect to the SQL Server pod with Azure Data Studio
# Retrieve external IP address
ip=$(kubectl get services | grep mssql | cut -c45-60)
echo $ip
# Simulate a failure by killing the pod. Delete pod exactkly does it.
kubectl delete pod ${podname}
# Wait one second
echo Waiting 3 second to show newly started pod
sleep 3
# now retrieve the running POD and you see the that POD name is different because Kubernetes recreated
#it after we deleted the earlier one
echo Retrieving running pods
kubectl get pods
# Get all of the running components
kubectl get all
# for Troubelshooting purpose you can use this command to view the events
kubectl describe pod -l app=mssql
# Display the container logs
kubectl logs -l app=mssql
Failure testing
For failure testing, we need to copy the database to the AKS cluster with the kubectl cp command and then we need to restore the database as depicted below.

Now when we connect to the SQL server and test any query it works file.

The same query works when we delete the pod because Kubernetes recreates a new POD and attaches it to PVC.
I hope you enjoyed this blog and it will be useful for you to implement it in your environment.
[…] Previous […]
[…] Another business case is to create a highly available database cluster with Kubernetes. Here is a link with a straightforward setup for Azure. https://rajanieshkaushikk.com/2021/02/27/how-to-deploy-sql-server-containers-to-a-kubernetes-cluster… […]